
Narzędzia do automatyzacji eksploracyjnej analizy danych (EDA) w Python
Zrozumienie danych jest pierwszym i najważniejszym krokiem w Data Science i budowie dobrego modelu uczenia maszynowego. Służy do tego analiza eksploracyjna danych (EDA, ang. Exploratory Data Analysis), która jest iteracyjnym, ekscytującym, ale często bardzo żmudnym procesem. Proces zrozumienia i przygotowania danych, którego EDA jest nieodłączną częścią stanowi nawet 80% całego czasu poświęconego na budowę modelu. Z pomocą przychodzi automatyzacja eksploracji, która jest kluczem do usystematyzowania tego procesu i redukcji kosztów.
Biblioteki w Python przeznaczone do manipulacji danymi, wizualizacji i uczenia maszynowego jak pandas, scikit-learn, czy seaborn, zawierają w sobie narzędzia, które analizę ułatwiają, jednak nie są stworzone z myślą o automatyzacji powtarzalnych czynności. Ta jest zostawiana twórcom eksperymentów i programistom. Dlatego powstały narzędzia, które automatyzują częściowo eksplorację danych z poziomu środowiska Jupyter Lab / Jupyter Notebook.
Niżej opisane narzędzia służą do generowania raportów z danych, ich opisu statystycznego, wizualizacji rozkładów, korelacji, informacji o brakujących danych, itp. Informacje te są niezbędne do podejmowania dalszych decyzji przy budowanie modeli uczenia maszynowego.
Do wizualizacji narzędzi użyłem danych dostępnych w Bazie Danych Lokalnych GUS.
D-Tale
D-Tale to obecnie najlepsze narzędzie do eksploracyjnej analizy danych, które oprócz podstawowych informacji statystycznych o zmiennych ma rozbudowany moduł wizualizacji danych za pomocą wszelkiej maści interaktywnych wykresów 2 i 3-wymiarowych. Co więcej D-Tale umożliwia również edycję danych w komórkach, dodawanie kolumn i stosowanie operacji. Jest więc D-Tale prawie jak MS Excel, Power BI lub Tableau. Wisienką na torcie jest możliwość wygenerowania kodu z „wyklikanej” analizy.
Instalacja:
# conda
conda install dtale -c conda-forge
# if you want to also use "Export to PNG" for charts
conda install -c plotly python-kaleido# PyPI
pip install dtale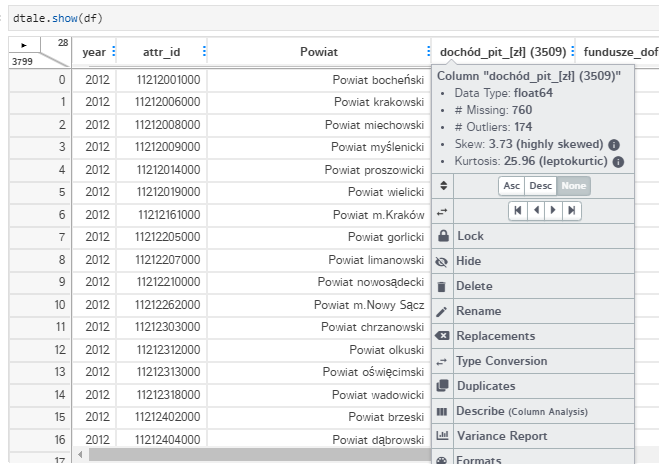
Arkusz z danymi przypomina MS Excel. Nagłówek kolumny zawiera podstawowe dane statystyczne o zawartych w niej danych oraz dodatkowe opcje do analizy i manipulacji tą kolumną od zmiany nazwy, położenia w arkuszu po zmianę typu, sortowanie i filtrowanie. Każdą komórkę można ręcznie edytować, ale również uruchamiać funkcje zmieniające wartości. Można też dodawać nowe kolumny i wypełniać wartościami będącymi agregatami lub funkcjami istniejących danych, szeregami czasowymi lub generować losowe dane. Możliwości jest bardzo wiele i to wszystko bez jednej linijki kodu.
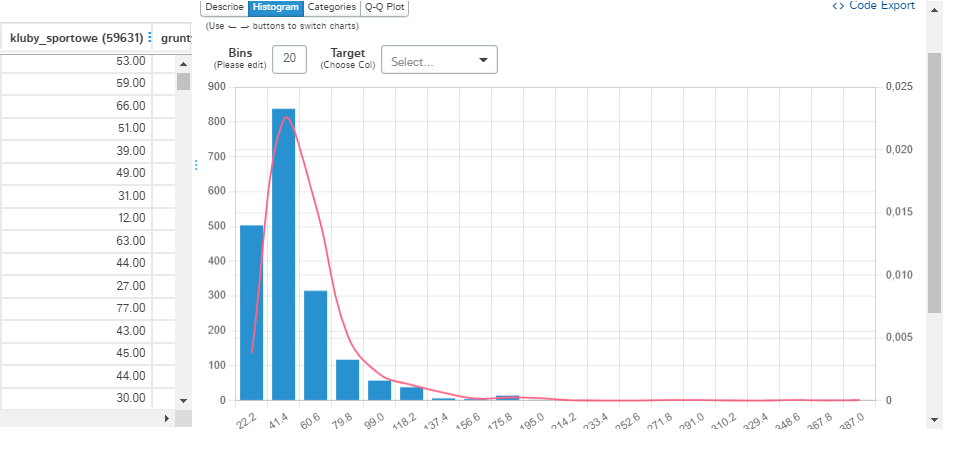
D-Tale w przejrzysty sposób prezentuje graficznie informacje o kolumnie na dodatkowym bocznym panelu. Oprócz wykresu pudełkowego do dyspozycji jest konfigurowalny histogram, wykres z podziałem na kategorie oraz wykres kwantyl-kwantyl (QQ). Górne wysuwające się menu (podobnie jak to ukryte pod strzałką w lewym górnym rogu arkusza) udostępnia oprócz akcji na danych kolejne moduły analiz, w tym PPS (ang. Predictive Power Score) obok zwykłej korelacji, bardzo rozbudowany moduł wykresów, a nawet graf połączeń jeśli dane taka informację ze sobą niosą.
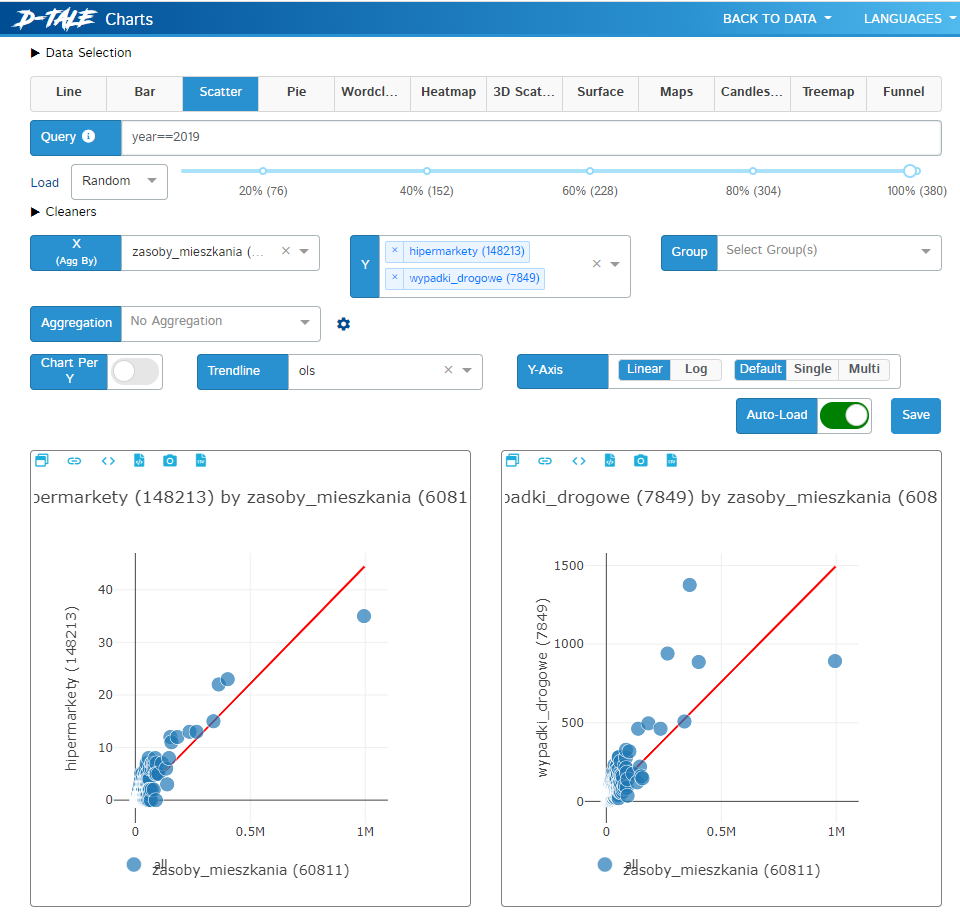
Wykresy otwierane są w osobnym oknie przeglądarki. Umożliwiają graficzną analizę 2- i 3-wymiarową i liniami trendów. Co więcej, można dodać animację zmian wg dowolnej zmiennej, co jest szczególnie przydatne przy szeregach czasowych. Dostępna jest również chmura słów oraz mapy. Dane można filtrować przed rysowaniem w taki sam sposób jak w pandas instrukcją query.
Ponieważ wykresy są interaktywne dzięki plotly, to praca z D-Tale przypomina trochę Microsoft Power BI lub Tableau.
Do generowania wykresów D-Tale używa flask i plotly uruchamiając lokalny serwer www (trzeba pamiętać o odblokowaniu portu na firewall’u, inaczej nie będzie widać wykresów). Parametry modułu wykresów można zapisywać w postaci linku URL z parametrami lub eksportując wygenerowany kod Python.
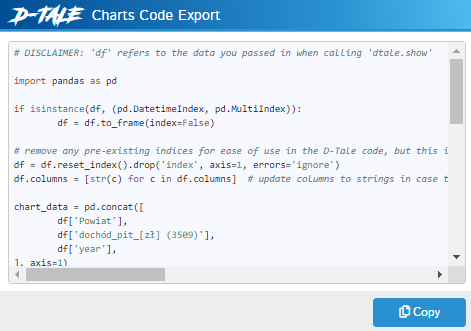
Wspomniane wyżej generowanie kodu działa praktycznie z każdego miejsca, więc możemy w łatwy sposób zachować coś co uzyskaliśmy dzięki ciężkiej pracy, a nawet wersjonować elementy analizy za pomocą wersjonowania kodu.
DataPrep
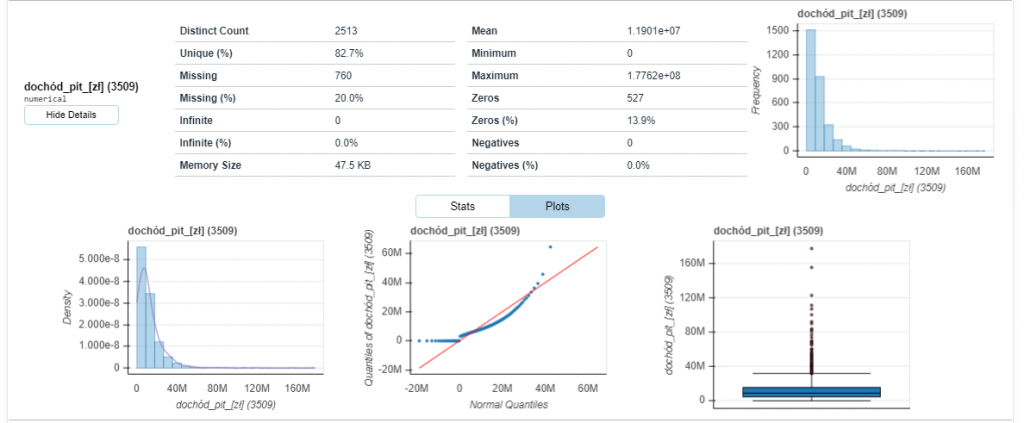
Nie jest tak rozbudowany jak D-Tale, posiada podstawowe informacje i wizualizacje zmiennych, ale za to jest bardzo szybki przy obsłudze dużych zbiorów danych ze względu na użycie biblioteki dask.
Podobnie jak w D-Tale przy każdej zmiennej prezentowany jest histogram, wykres pudełkowy i wykres QQ. Dostępne są mapy korelacji i analiza braków danych.
Instalacja
# conda
conda install dataprep -c conda-forge# PyPI
pip install -U dataprepSweetVIZ
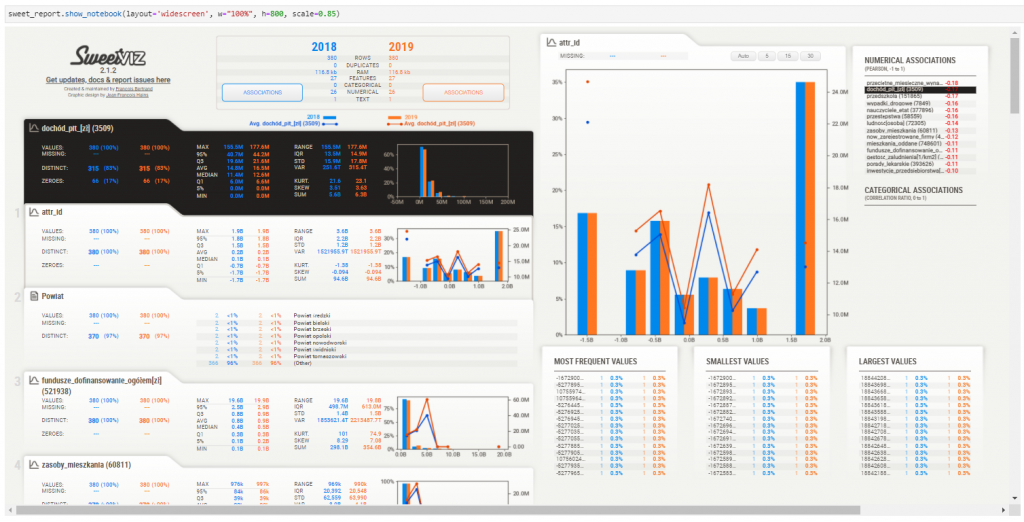
Narzędzie podobne do DataPrep, pozwala nie tylko na podstawową analizę poszczególnych zmiennych, ale także wzajemną analizę dwóch zbiorów, np. zbiór trenujący i testujący, czy dwa okresy w szeregach czasowych. Mimo, że interfejs jest dość atrakcyjny wizualnie, to jednak jest dla mnie mało czytelny, szczególnie przy większej ilości zmiennych.
Instalacja
# conda
conda install sweetviz -c conda-forge# PyPI
pip install -U sweetvizpandas_profiling
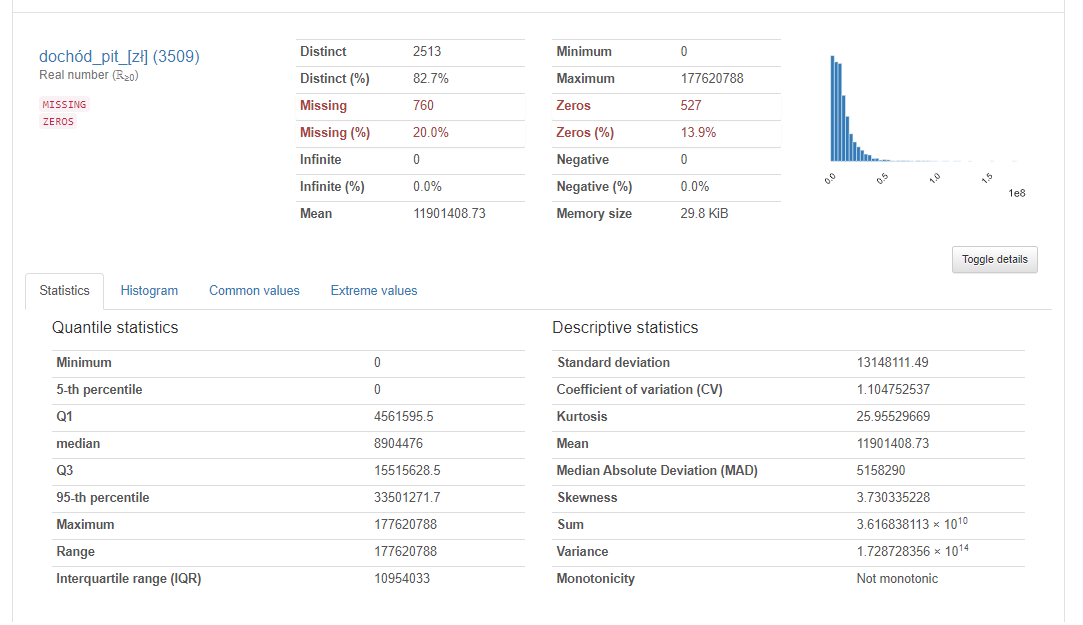
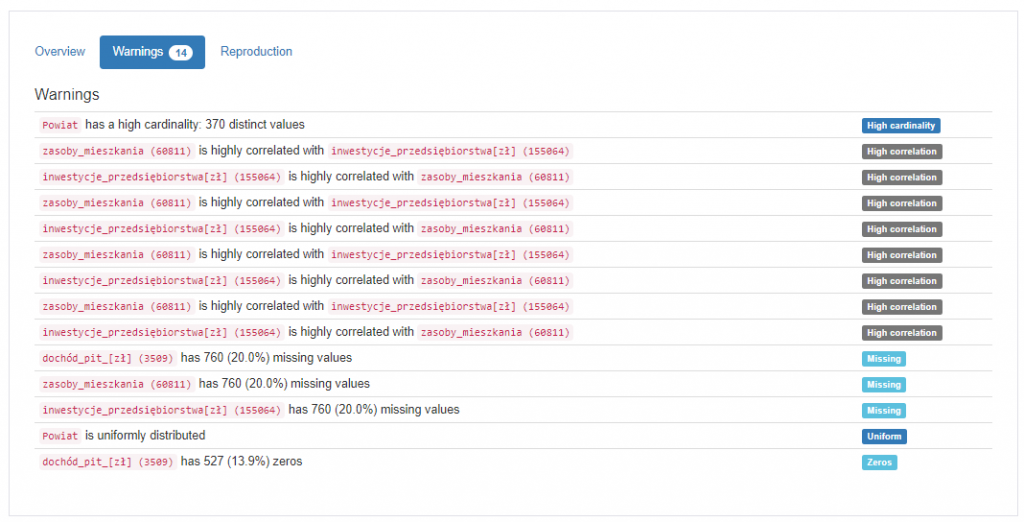
Podobnie jak DataPrep i SweetVIZ biblioteka pandas_profiling przedstawia podstawowe dane statystyczne o zmiennych, histogram i korelację pomiędzy zmiennymi, choć w uboższej formie. Ciekawym rozwiązaniem jest lista ostrzeżeń, gdy zmienne są skorelowane lub zawierają braki danych. Niestety jej największym problemem jest niska wydajność połączona z dużym zapotrzebowaniem na pamięć RAM i CPU przy generowaniu i wyświetlaniu raportów w Jupyter Lab, co widać już przy kilkunastu zmiennych.
Instalacja
# conda
conda install pandas-profiling -c conda-forge# PyPI
pip install -U pandas-profilingPodsumowując, w zasadzie mógłbym poprzestać na prezentacji D-Tale, każde jednak z konkurencyjnych narzędzi, pomimo swoich uboższych możliwości, ma unikalne cechy warte opisania. Każde z nich też jest utrzymywane i rozwijane.




